
ж‘ҳиҮӘhttp://book.51cto.com/art/200906/132406.htm
В
8.4.5В зҙўеј•зҡ„еҲ©ејҠдёҺеҰӮдҪ•еҲӨе®ҡпјҢжҳҜеҗҰйңҖиҰҒзҙўеј•
В
зӣёдҝЎиҜ»иҖ…йғҪзҹҘйҒ“зҙўеј•иғҪеӨҹжһҒеӨ§ең°жҸҗй«ҳж•°жҚ®жЈҖзҙўзҡ„ж•ҲзҺҮпјҢи®©Query жү§иЎҢеҫ—жӣҙеҝ«пјҢдҪҶжҳҜеҸҜиғҪ并дёҚжҳҜжҜҸдёҖдҪҚжңӢеҸӢйғҪжё…жҘҡзҙўеј•еңЁжһҒеӨ§жҸҗй«ҳжЈҖзҙўж•ҲзҺҮзҡ„еҗҢж—¶пјҢд№ҹз»ҷж•°жҚ®еә“еёҰжқҘдәҶдёҖдәӣиҙҹйқўзҡ„еҪұе“ҚгҖӮдёӢйқўе°ұеҲҶеҲ«еҜ№ MySQL дёӯзҙўеј•зҡ„еҲ©дёҺејҠеҒҡдёҖдёӘз®ҖеҚ•зҡ„еҲҶжһҗгҖӮ
В
зҙўеј•зҡ„еҘҪеӨ„
В
зҙўеј•еёҰжқҘзҡ„зӣҠеӨ„еҸҜиғҪеҫҲеӨҡиҜ»иҖ…дјҡи®ӨдёәеҸӘжҳҜ"иғҪеӨҹжҸҗй«ҳж•°жҚ®жЈҖзҙўзҡ„ж•ҲзҺҮпјҢйҷҚдҪҺж•°жҚ®еә“зҡ„IOжҲҗжң¬"гҖӮ
В
зЎ®е®һпјҢеңЁж•°жҚ®еә“дёӯиЎЁзҡ„жҹҗдёӘеӯ—ж®өеҲӣе»әзҙўеј•пјҢжүҖеёҰжқҘзҡ„жңҖеӨ§зӣҠеӨ„е°ұжҳҜе°ҶиҜҘеӯ—ж®өдҪңдёәжЈҖзҙўжқЎд»¶ж—¶еҸҜд»ҘжһҒеӨ§ең°жҸҗй«ҳжЈҖзҙўж•ҲзҺҮпјҢеҠ еҝ«жЈҖзҙўж—¶й—ҙпјҢйҷҚдҪҺжЈҖзҙўиҝҮзЁӢдёӯйЎ»иҰҒиҜ» еҸ–зҡ„ж•°жҚ®йҮҸгҖӮдҪҶжҳҜзҙўеј•еёҰжқҘзҡ„收зӣҠеҸӘжҳҜжҸҗй«ҳиЎЁж•°жҚ®зҡ„жЈҖзҙўж•ҲзҺҮеҗ—пјҹеҪ“然дёҚжҳҜпјҢзҙўеј•иҝҳжңүдёҖдёӘйқһеёёйҮҚиҰҒзҡ„з”ЁйҖ”пјҢйӮЈе°ұжҳҜйҷҚдҪҺж•°жҚ®зҡ„жҺ’еәҸжҲҗжң¬гҖӮ
жҲ‘们зҹҘ йҒ“пјҢжҜҸдёӘзҙўеј•дёӯзҡ„ж•°жҚ®йғҪжҳҜжҢүз…§зҙўеј•й”®й”®еҖјиҝӣиЎҢжҺ’еәҸеҗҺеӯҳж”ҫзҡ„пјҢжүҖд»ҘпјҢеҪ“Query иҜӯеҸҘдёӯеҢ…еҗ«жҺ’еәҸеҲҶз»„ж“ҚдҪңж—¶пјҢеҰӮжһңжҺ’еәҸеӯ—ж®өе’Ңзҙўеј•й”®еӯ—ж®өеҲҡеҘҪдёҖиҮҙпјҢMySQL Query Optimizer е°ұдјҡе‘ҠиҜү mysqld еңЁеҸ–еҫ—ж•°жҚ®еҗҺдёҚз”ЁжҺ’еәҸдәҶпјҢеӣ дёәж №жҚ®зҙўеј•еҸ–еҫ—зҡ„ж•°жҚ®е·Із»Ҹж»Ўи¶іе®ўжҲ·зҡ„жҺ’еәҸиҰҒжұӮгҖӮ
В
йӮЈеҰӮжһңжҳҜеҲҶз»„ж“ҚдҪңе‘ўпјҹеҲҶз»„ж“ҚдҪңжІЎеҠһжі•зӣҙжҺҘеҲ©з”Ёзҙўеј•е®ҢжҲҗгҖӮдҪҶжҳҜеҲҶз»„ж“ҚдҪңжҳҜйЎ»иҰҒе…ҲиҝӣиЎҢжҺ’еәҸ然еҗҺеҲҶз»„зҡ„пјҢжүҖд»ҘеҪ“Query иҜӯеҸҘдёӯеҢ…еҗ«еҲҶз»„ж“ҚдҪңпјҢиҖҢдё”еҲҶз»„еӯ—ж®өд№ҹеҲҡеҘҪе’Ңзҙўеј•й”®еӯ—ж®өдёҖиҮҙпјҢйӮЈд№Ҳmysqld еҗҢж ·еҸҜд»ҘеҲ©з”Ёзҙўеј•е·Із»ҸжҺ’еҘҪеәҸзҡ„иҝҷдёӘзү№жҖ§пјҢзңҒз•ҘжҺүеҲҶз»„дёӯзҡ„жҺ’еәҸж“ҚдҪңгҖӮ
В
жҺ’еәҸеҲҶз»„ж“ҚдҪңдё»иҰҒж¶ҲиҖ—зҡ„жҳҜеҶ…еӯҳе’Ң CPU иө„жәҗпјҢеҰӮжһңиғҪеӨҹеңЁиҝӣиЎҢжҺ’еәҸеҲҶз»„ж“ҚдҪңдёӯеҲ©з”ЁеҘҪзҙўеј•пјҢе°ҶдјҡжһҒеӨ§ең°йҷҚдҪҺCPUиө„жәҗзҡ„ж¶ҲиҖ—гҖӮ
В
зҙўеј•зҡ„ејҠз«Ҝ
В
зҙўеј•зҡ„зӣҠеӨ„е·Із»Ҹжё…жҘҡдәҶпјҢдҪҶжҳҜжҲ‘们дёҚиғҪеҸӘзңӢеҲ°иҝҷдәӣзӣҠеӨ„пјҢ并и®Өдёәзҙўеј•жҳҜи§ЈеҶі Query дјҳеҢ–зҡ„еңЈз»ҸпјҢеҸӘиҰҒеҸ‘зҺ° Query иҝҗиЎҢдёҚеӨҹеҝ«е°ұе°Ҷ WHERE еӯҗеҸҘдёӯзҡ„жқЎд»¶е…ЁйғЁж”ҫеңЁзҙўеј•дёӯгҖӮ
В
зЎ®е®һпјҢзҙўеј•иғҪеӨҹжһҒеӨ§ең°жҸҗй«ҳж•°жҚ®жЈҖзҙўж•ҲзҺҮпјҢд№ҹиғҪеӨҹж”№е–„жҺ’еәҸеҲҶз»„ж“ҚдҪңзҡ„жҖ§иғҪпјҢдҪҶжңүдёҚиғҪеҝҪз•Ҙзҡ„дёҖдёӘй—®йўҳе°ұжҳҜзҙўеј•жҳҜе®Ңе…ЁзӢ¬з«ӢдәҺеҹәзЎҖж•°жҚ®д№ӢеӨ–зҡ„дёҖйғЁеҲҶж•°жҚ®гҖӮеҒҮ и®ҫеңЁTable ta дёӯзҡ„Column ca еҲӣе»әдәҶзҙўеј• idx_ta_caпјҢйӮЈд№Ҳд»»дҪ•жӣҙж–° Column ca зҡ„ж“ҚдҪңпјҢMySQLеңЁжӣҙж–°иЎЁдёӯ Column caзҡ„еҗҢж—¶пјҢйғҪйЎ»иҰҒжӣҙж–°Column ca зҡ„зҙўеј•ж•°жҚ®пјҢи°ғж•ҙеӣ дёәжӣҙж–°еёҰжқҘй”®еҖјеҸҳеҢ–зҡ„зҙўеј•дҝЎжҒҜгҖӮиҖҢеҰӮжһңжІЎжңүеҜ№ Column ca иҝӣиЎҢзҙўеј•пјҢMySQLиҰҒеҒҡзҡ„д»…д»…жҳҜжӣҙж–°иЎЁдёӯ Column ca зҡ„дҝЎжҒҜгҖӮиҝҷж ·пјҢжңҖжҳҺжҳҫзҡ„иө„жәҗж¶ҲиҖ—е°ұжҳҜеўһеҠ дәҶжӣҙж–°жүҖеёҰжқҘзҡ„ IO йҮҸе’Ңи°ғж•ҙзҙўеј•жүҖиҮҙзҡ„и®Ўз®—йҮҸгҖӮжӯӨеӨ–пјҢColumn ca зҡ„зҙўеј•idx_ta_caйЎ»иҰҒеҚ з”ЁеӯҳеӮЁз©әй—ҙпјҢиҖҢдё”йҡҸзқҖ Table ta ж•°жҚ®йҮҸзҡ„еўһеҠ пјҢidx_ta_ca жүҖеҚ з”Ёзҡ„з©әй—ҙд№ҹдјҡдёҚж–ӯеўһеҠ пјҢжүҖд»Ҙзҙўеј•иҝҳдјҡеёҰжқҘеӯҳеӮЁз©әй—ҙиө„жәҗж¶ҲиҖ—зҡ„еўһеҠ гҖӮ
В
еҰӮдҪ•еҲӨе®ҡжҳҜеҗҰйЎ»иҰҒеҲӣе»әзҙўеј•
В
еңЁдәҶи§ЈдәҶзҙўеј•зҡ„еҲ©дёҺејҠд№ӢеҗҺпјҢйӮЈжҲ‘们еҲ°еә•иҜҘеҰӮдҪ•жқҘеҲӨж–ӯжҹҗдёӘзҙўеј•жҳҜеҗҰеә”иҜҘеҲӣе»әе‘ўпјҹ
В
е®һйҷ…дёҠпјҢ并没жңүдёҖдёӘйқһеёёжҳҺзЎ®зҡ„е®ҡеҫӢеҸҜд»Ҙжё…жҷ°ең°е®ҡд№үд»Җд№Ҳеӯ—ж®өеә”иҜҘеҲӣе»әзҙўеј•пјҢд»Җд№Ҳеӯ—ж®өдёҚиҜҘеҲӣе»әзҙўеј•гҖӮеӣ дёәеә”з”ЁеңәжҷҜе®һеңЁжҳҜеӨӘеӨҚжқӮпјҢеӯҳеңЁеӨӘеӨҡзҡ„е·®ејӮгҖӮеҪ“然пјҢиҝҳжҳҜд»Қ然иғҪеӨҹжүҫеҲ°еҮ зӮ№еҹәжң¬зҡ„еҲӨе®ҡзӯ–з•ҘжқҘеё®еҠ©еҲҶжһҗзҡ„гҖӮ
В
1. иҫғйў‘з№Ғзҡ„дҪңдёәжҹҘиҜўжқЎд»¶зҡ„еӯ—ж®өеә”иҜҘеҲӣе»әзҙўеј•
В
жҸҗй«ҳж•°жҚ®жҹҘиҜўжЈҖзҙўзҡ„ж•ҲзҺҮжңҖжңүж•Ҳзҡ„еҠһжі•е°ұжҳҜеҮҸе°‘йЎ»иҰҒи®ҝй—®зҡ„ж•°жҚ®йҮҸпјҢд»ҺдёҠйқўзҙўеј•зҡ„зӣҠеӨ„дёӯжҲ‘们зҹҘйҒ“пјҢзҙўеј•жӯЈжҳҜеҮҸе°‘йҖҡиҝҮзҙўеј•й”®еӯ—ж®өдҪңдёәжҹҘиҜўжқЎд»¶зҡ„ Query зҡ„IOйҮҸд№ӢжңҖжңүж•ҲжүӢж®өгҖӮжүҖд»ҘдёҖиҲ¬жқҘиҜҙеә”иҜҘдёәиҫғдёәйў‘з№Ғзҡ„жҹҘиҜўжқЎд»¶еӯ—ж®өеҲӣе»әзҙўеј•гҖӮ
В
2. е”ҜдёҖжҖ§еӨӘе·®зҡ„еӯ—ж®өдёҚйҖӮеҗҲеҚ•зӢ¬еҲӣе»әзҙўеј•пјҢеҚідҪҝйў‘з№ҒдҪңдёәжҹҘиҜўжқЎд»¶
В
е”ҜдёҖжҖ§еӨӘе·®зҡ„еӯ—ж®өдё»иҰҒжҳҜжҢҮе“Әдәӣе‘ўпјҹеҰӮзҠ¶жҖҒеӯ—ж®өгҖҒзұ»еһӢеӯ—ж®өзӯүиҝҷдәӣеӯ—ж®өдёӯеӯҳж”ҫзҡ„ж•°жҚ®еҸҜиғҪжҖ»е…ұе°ұжҳҜйӮЈд№ҲеҮ дёӘжҲ–еҮ еҚҒдёӘеҖјйҮҚеӨҚдҪҝз”ЁпјҢжҜҸдёӘеҖјйғҪдјҡеӯҳеңЁдәҺжҲҗеҚғдёҠдёҮ жҲ–жӣҙеӨҡзҡ„и®°еҪ•дёӯгҖӮеҜ№дәҺиҝҷзұ»еӯ—ж®өпјҢе®Ңе…ЁжІЎжңүеҝ…иҰҒеҲӣе»әеҚ•зӢ¬зҡ„зҙўеј•гҖӮеӣ дёәеҚідҪҝеҲӣе»әдәҶзҙўеј•пјҢMySQL Query Optimizer еӨ§еӨҡж•°ж—¶еҖҷд№ҹдёҚдјҡеҺ»йҖүжӢ©дҪҝз”ЁпјҢеҰӮжһңд»Җд№Ҳж—¶еҖҷ MySQL Query OptimizerйҖүжӢ©дәҶиҝҷз§Қзҙўеј•пјҢйӮЈд№ҲйқһеёёйҒ—жҶҫең°е‘ҠиҜүдҪ пјҢиҝҷеҸҜиғҪдјҡеёҰжқҘжһҒеӨ§зҡ„жҖ§иғҪй—®йўҳгҖӮз”ұдәҺзҙўеј•еӯ—ж®өдёӯжҜҸдёӘеҖјйғҪеҗ«жңүеӨ§йҮҸзҡ„и®°еҪ•пјҢйӮЈд№ҲеӯҳеӮЁеј•ж“ҺеңЁж №жҚ®зҙўеј• и®ҝй—®ж•°жҚ®зҡ„ж—¶еҖҷдјҡеёҰжқҘеӨ§йҮҸзҡ„йҡҸжңәIOпјҢз”ҡиҮіжңүдәӣж—¶еҖҷиҝҳдјҡеҮәзҺ°еӨ§йҮҸзҡ„йҮҚеӨҚIOгҖӮ
В
иҝҷдё»иҰҒжҳҜз”ұдәҺж•°жҚ®еҹәдәҺзҙўеј•жү«жҸҸзҡ„зү№зӮ№еј•иө·зҡ„гҖӮеҪ“жҲ‘们йҖҡиҝҮзҙўеј•и®ҝй—®иЎЁдёӯж•°жҚ®ж—¶пјҢMySQL дјҡжҢүз…§зҙўеј•й”®зҡ„й”®еҖјйЎәеәҸжқҘдҫқеәҸи®ҝй—®гҖӮдёҖиҲ¬жқҘиҜҙпјҢжҜҸдёӘж•°жҚ®йЎөдёӯеӨ§йғҪдјҡеӯҳж”ҫеӨҡжқЎи®°еҪ•пјҢдҪҶжҳҜиҝҷдәӣи®°еҪ•еҸҜиғҪеӨ§еӨҡж•°йғҪдёҚдјҡе’ҢдҪ жүҖдҪҝз”Ёзҡ„зҙўеј•й”®зҡ„й”®еҖјйЎәеәҸдёҖиҮҙгҖӮ
В
еҒҮеҰӮжңүд»ҘдёӢеңәжҷҜпјҢжҲ‘们йҖҡиҝҮзҙўеј•жҹҘжүҫй”®еҖјдёәAе’ҢBзҡ„жҹҗдәӣж•°жҚ®гҖӮеңЁйҖҡиҝҮAй”®еҖјжүҫеҲ°з¬¬дёҖжқЎж»Ўи¶іиҰҒжұӮзҡ„и®°еҪ•еҗҺпјҢдјҡиҜ»еҸ–иҝҷжқЎи®°еҪ•жүҖеңЁзҡ„ X ж•°жҚ®йЎөпјҢ然еҗҺ继з»ӯеҫҖдёӢжҹҘжүҫзҙўеј•пјҢеҸ‘зҺ° A й”®еҖјжүҖеҜ№еә”зҡ„еҸҰеӨ–дёҖжқЎи®°еҪ•д№ҹж»Ўи¶іиҰҒжұӮпјҢдҪҶжҳҜиҝҷжқЎи®°еҪ•дёҚеңЁ X ж•°жҚ®йЎөдёҠпјҢиҖҢеңЁYж•°жҚ®йЎөдёҠпјҢиҝҷж—¶еҖҷеӯҳеӮЁеј•ж“Һе°ұдјҡдёўејғXж•°жҚ®йЎөпјҢиҖҢиҜ»еҸ–Yж•°жҚ®йЎөгҖӮеҰӮжӯӨ继з»ӯдёҖзӣҙеҲ°жҹҘжүҫе®ҢAй”®еҖјжүҖеҜ№еә”зҡ„жүҖжңүи®°еҪ•гҖӮ然еҗҺиҪ®еҲ°Bй”®еҖјдәҶпјҢиҝҷж—¶еҸ‘зҺ° жӯЈеңЁжҹҘжүҫзҡ„и®°еҪ•еҸҲеңЁXж•°жҚ®йЎөдёҠпјҢеҸҜд№ӢеүҚиҜ»еҸ–зҡ„ X ж•°жҚ®йЎөе·Із»Ҹиў«дёўејғдәҶпјҢеҸӘиғҪеҶҚж¬ЎиҜ»еҸ– X ж•°жҚ®йЎөгҖӮиҝҷж—¶еҖҷпјҢе®һйҷ…дёҠе·Із»ҸйҮҚеӨҚиҜ»еҸ– X ж•°жҚ®йЎөдёӨж¬ЎдәҶгҖӮеңЁз»§з»ӯеҫҖеҗҺзҡ„жҹҘжүҫдёӯпјҢеҸҜиғҪиҝҳдјҡеҮәзҺ°дёҖж¬ЎеҸҲдёҖж¬Ўзҡ„йҮҚеӨҚиҜ»еҸ–пјҢиҝҷж— з–‘з»ҷеӯҳеӮЁеј•ж“ҺжһҒеӨ§ең°еўһеҠ дәҶIOи®ҝй—®йҮҸгҖӮ
В
дёҚд»…еҰӮжӯӨпјҢеҰӮжһңдёҖдёӘй”®еҖјеҜ№еә”дәҶеӨӘеӨҡзҡ„ж•°жҚ®и®°еҪ•пјҢд№ҹе°ұжҳҜиҜҙйҖҡиҝҮиҜҘй”®еҖјдјҡиҝ”еӣһеҚ ж•ҙдёӘиЎЁжҜ”дҫӢеҫҲеӨ§зҡ„и®°еҪ•ж—¶пјҢз”ұдәҺж №жҚ®зҙўеј•жү«жҸҸдә§з”ҹзҡ„йғҪжҳҜйҡҸжңә IOпјҢе…¶ж•ҲзҺҮжҜ”иҝӣиЎҢе…ЁиЎЁжү«жҸҸзҡ„йЎәеәҸIOж•ҲзҺҮдҪҺеҫҲеӨҡпјҢеҚідҪҝдёҚдјҡеҮәзҺ°йҮҚеӨҚ IO зҡ„иҜ»еҸ–пјҢеҗҢж ·дјҡйҖ жҲҗж•ҙдҪ“ IO жҖ§иғҪзҡ„дёӢйҷҚгҖӮ
В
еҫҲеӨҡжҜ”иҫғжңүз»ҸйӘҢзҡ„ Query и°ғдјҳ专家з»ҸеёёиҜҙпјҢеҪ“дёҖжқЎQueryиҝ”еӣһзҡ„ж•°жҚ®и¶…иҝҮдәҶе…ЁиЎЁзҡ„ 15%ж—¶пјҢе°ұдёҚеә”иҜҘеҶҚдҪҝз”Ёзҙўеј•жү«жҸҸжқҘе®ҢжҲҗиҝҷдёӘ Query дәҶгҖӮеҜ№дәҺ"15%"иҝҷдёӘж•°еӯ—жҲ‘们并дёҚиғҪеҲӨе®ҡжҳҜеҗҰеҫҲеҮҶзЎ®пјҢдҪҶжҳҜиҮіе°‘дҫ§йқўиҜҒжҳҺдәҶе”ҜдёҖжҖ§еӨӘе·®зҡ„еӯ—ж®ө并дёҚйҖӮеҗҲеҲӣе»әзҙўеј•гҖӮ
В
3. жӣҙж–°йқһеёёйў‘з№Ғзҡ„еӯ—ж®өдёҚйҖӮеҗҲеҲӣе»әзҙўеј•
В
дёҠйқўеңЁзҙўеј•зҡ„ејҠз«Ҝдёӯе·Із»ҸеҲҶжһҗиҝҮдәҶпјҢзҙўеј•дёӯзҡ„еӯ—ж®өиў«жӣҙж–°зҡ„ж—¶еҖҷпјҢдёҚд»…иҰҒжӣҙж–°иЎЁдёӯзҡ„ж•°жҚ®пјҢиҝҳиҰҒжӣҙж–°зҙўеј•ж•°жҚ®пјҢд»ҘзЎ®дҝқзҙўеј•дҝЎжҒҜжҳҜеҮҶзЎ®зҡ„гҖӮиҝҷдёӘй—®йўҳиҮҙдҪҝIO и®ҝй—®йҮҸиҫғеӨ§еўһеҠ пјҢдёҚд»…д»…еҪұе“ҚдәҶжӣҙж–° Query зҡ„е“Қеә”ж—¶й—ҙпјҢиҝҳеҪұе“ҚдәҶж•ҙдёӘеӯҳеӮЁзі»з»ҹзҡ„иө„жәҗж¶ҲиҖ—пјҢеҠ еӨ§дәҶж•ҙдёӘеӯҳеӮЁзі»з»ҹзҡ„иҙҹиҪҪгҖӮ
В
еҪ“然пјҢ并дёҚжҳҜеӯҳеңЁжӣҙж–°зҡ„еӯ—ж®өе°ұйҖӮеҗҲеҲӣе»әзҙўеј•пјҢд»ҺеҲӨе®ҡзӯ–з•Ҙзҡ„з”ЁиҜӯдёҠд№ҹеҸҜд»ҘзңӢеҮәпјҢжҳҜ"йқһеёёйў‘з№Ғ"зҡ„еӯ—ж®өгҖӮеҲ°еә•д»Җд№Ҳж ·зҡ„жӣҙж–°йў‘зҺҮеә”иҜҘз®—жҳҜ"йқһеёёйў‘з№Ғ"е‘ўпјҹ жҜҸз§’пјҹжҜҸеҲҶй’ҹпјҹиҝҳжҳҜжҜҸе°Ҹж—¶е‘ўпјҹиҜҙе®һиҜқпјҢиҝҳзңҹйҡҫе®ҡд№үгҖӮеҫҲеӨҡж—¶еҖҷжҳҜйҖҡиҝҮжҜ”иҫғеҗҢдёҖж—¶й—ҙж®өеҶ…иў«жӣҙж–°зҡ„ж¬Ўж•°е’ҢеҲ©з”ЁиҜҘеӯ—ж®өдҪңдёәжқЎд»¶зҡ„жҹҘиҜўж¬Ўж•°жқҘеҲӨж–ӯзҡ„пјҢеҰӮжһңйҖҡиҝҮиҜҘеӯ—ж®ө зҡ„жҹҘиҜўе№¶дёҚжҳҜеҫҲеӨҡпјҢеҸҜиғҪеҮ дёӘе°Ҹж—¶жҲ–жҳҜжӣҙй•ҝжүҚдјҡжү§иЎҢдёҖж¬ЎпјҢжӣҙж–°еҸҚиҖҢжҜ”жҹҘиҜўжӣҙйў‘з№ҒпјҢйӮЈиҝҷж ·зҡ„еӯ—ж®өиӮҜе®ҡдёҚйҖӮеҗҲеҲӣе»әзҙўеј•гҖӮеҸҚд№ӢпјҢеҰӮжһңжҲ‘们йҖҡиҝҮиҜҘеӯ—ж®өзҡ„жҹҘиҜўжҜ”иҫғйў‘ з№ҒпјҢдҪҶжӣҙ新并дёҚжҳҜзү№еҲ«еӨҡпјҢжҜ”еҰӮжҹҘиҜўеҮ еҚҒж¬ЎжҲ–жӣҙеӨҡжүҚеҸҜиғҪдјҡдә§з”ҹдёҖж¬Ўжӣҙж–°пјҢйӮЈжҲ‘дёӘдәәи§үеҫ—жӣҙж–°жүҖеёҰжқҘзҡ„йҷ„еҠ жҲҗжң¬д№ҹжҳҜеҸҜд»ҘжҺҘеҸ—зҡ„гҖӮ
В
4. дёҚдјҡеҮәзҺ°еңЁ WHERE еӯҗеҸҘдёӯзҡ„еӯ—ж®өдёҚиҜҘеҲӣе»әзҙўеј•
дёҚдјҡиҝҳжңүдәәдјҡй—®дёәд»Җд№Ҳеҗ§пјҹиҮӘе·ұд№ҹи§үеҫ—иҝҷжҳҜеәҹиҜқдәҶпјҢе“Ҳе“ҲпјҒ
8.4.6В еҚ•й”®зҙўеј•иҝҳжҳҜз»„еҗҲзҙўеј•
В
еңЁеӨ§жҰӮдәҶи§ЈдәҶMySQL еҗ„з§Қзұ»еһӢзҡ„зҙўеј•пјҢд»ҘеҸҠзҙўеј•жң¬иә«зҡ„еҲ©ејҠдёҺеҲӨж–ӯдёҖдёӘеӯ—ж®өжҳҜеҗҰйЎ»иҰҒеҲӣе»әзҙўеј•д№ӢеҗҺпјҢе°ұиҰҒзқҖжүӢеҲӣе»әзҙўеј•жқҘдјҳеҢ–Query дәҶгҖӮеңЁеҫҲеӨҡж—¶еҖҷпјҢWHERE еӯҗеҸҘдёӯзҡ„иҝҮж»ӨжқЎд»¶е№¶дёҚеҸӘжҳҜй’ҲеҜ№дәҺеҚ•дёҖзҡ„жҹҗдёӘеӯ—ж®өпјҢз»ҸеёёдјҡжңүеӨҡдёӘеӯ—ж®өдёҖиө·дҪңдёәжҹҘиҜўиҝҮж»ӨжқЎд»¶еӯҳеңЁдәҺ WHERE еӯҗеҸҘдёӯгҖӮеңЁиҝҷз§Қж—¶еҖҷпјҢе°ұеҝ…йЎ»иҰҒеҲӨж–ӯжҳҜиҜҘд»…д»…дёәиҝҮж»ӨжҖ§жңҖеҘҪзҡ„еӯ—ж®өе»әз«Ӣзҙўеј•пјҢиҝҳжҳҜиҜҘеңЁжүҖжңүеӯ—ж®өпјҲиҝҮж»ӨжқЎд»¶дёӯзҡ„пјүдёҠе»әз«ӢдёҖдёӘз»„еҗҲзҙўеј•гҖӮ
В
еҜ№дәҺиҝҷз§Қй—®йўҳпјҢеҫҲйҡҫжңүдёҖдёӘз»қеҜ№зҡ„е®ҡи®әпјҢйЎ»иҰҒд»ҺеӨҡж–№йқўжқҘеҲҶжһҗиҖғиҷ‘пјҢе№іиЎЎдёӨз§Қж–№жЎҲеҗ„иҮӘзҡ„дјҳеҠЈпјҢ然еҗҺйҖүжӢ©дёҖз§ҚжңҖдҪізҡ„ж–№жЎҲгҖӮеӣ дёәд»ҺдёҠдёҖиҠӮдёӯе·ІдәҶи§ЈеҲ°зҙўеј•еңЁжҸҗ й«ҳжҹҗдәӣжҹҘиҜўзҡ„жҖ§иғҪеҗҢж—¶пјҢд№ҹдјҡи®©жҹҗдәӣжӣҙж–°зҡ„ж•ҲзҺҮдёӢйҷҚгҖӮиҖҢз»„еҗҲзҙўеј•дёӯеӣ дёәжңүеӨҡдёӘеӯ—ж®өеӯҳеңЁпјҢзҗҶи®әдёҠиў«жӣҙж–°зҡ„еҸҜиғҪжҖ§иӮҜе®ҡжҜ”еҚ•й”®зҙўеј•иҰҒеӨ§еҫҲеӨҡпјҢиҝҷж ·еёҰжқҘзҡ„йҷ„еҠ жҲҗжң¬д№ҹ е°ұжҜ”еҚ•й”®зҙўеј•иҰҒй«ҳгҖӮдҪҶжҳҜпјҢеҪ“WHERE еӯҗеҸҘдёӯзҡ„жҹҘиҜўжқЎд»¶еҗ«жңүеӨҡдёӘеӯ—ж®өж—¶пјҢйҖҡиҝҮиҝҷеӨҡдёӘеӯ—ж®өе…ұеҗҢз»„жҲҗзҡ„з»„еҗҲзҙўеј•зҡ„жҹҘиҜўж•ҲзҺҮиӮҜе®ҡжҜ”еҸӘз”ЁиҝҮж»ӨжқЎд»¶дёӯзҡ„жҹҗдёҖдёӘеӯ—ж®өеҲӣе»әзҡ„зҙўеј•иҰҒй«ҳгҖӮеӣ дёәйҖҡиҝҮеҚ•й”®зҙўеј•иҝҮж»Өзҡ„ ж•°жҚ®е№¶дёҚе®Ңж•ҙпјҢе’Ңз»„еҗҲзҙўеј•зӣёжҜ”пјҢеӯҳеӮЁеј•ж“ҺйЎ»иҰҒи®ҝй—®жӣҙеӨҡзҡ„и®°еҪ•ж•°пјҢиҮӘ然е°ұдјҡи®ҝй—®жӣҙеӨҡзҡ„ж•°жҚ®йҮҸпјҢд№ҹе°ұжҳҜиҜҙйңҖиҰҒжӣҙй«ҳзҡ„ IO жҲҗжң¬гҖӮ
В
еҸҜиғҪжңүжңӢеҸӢдјҡиҜҙпјҢйӮЈеҸҜд»ҘеҲӣе»әеӨҡдёӘеҚ•й”®зҙўеј•е•ҠгҖӮзЎ®е®һеҸҜд»Ҙе°Ҷ WHERE еӯҗеҸҘдёӯзҡ„жҜҸдёҖдёӘеӯ—ж®өйғҪеҲӣе»әдёҖдёӘеҚ•й”®зҙўеј•гҖӮдҪҶжҳҜиҝҷж ·зңҹзҡ„жңүж•Ҳеҗ—пјҹеңЁиҝҷж ·зҡ„жғ…еҶөдёӢпјҢMySQL Query Optimizer еӨ§еӨҡж•°ж—¶еҖҷйғҪеҸӘдјҡйҖүжӢ©е…¶дёӯзҡ„дёҖдёӘзҙўеј•пјҢ然еҗҺж”ҫејғе…¶д»–зҡ„зҙўеј•гҖӮеҚідҪҝд»–йҖүжӢ©дәҶеҗҢж—¶еҲ©з”ЁдёӨдёӘжҲ–жӣҙеӨҡзҡ„зҙўеј•йҖҡиҝҮ INDEX_MERGE жқҘдјҳеҢ–жҹҘиҜўпјҢжүҖ收еҲ°зҡ„ж•ҲжһңеҸҜиғҪ并дёҚдјҡжҜ”йҖүжӢ©е…¶дёӯжҹҗдёҖдёӘеҚ•й”®зҙўеј•жӣҙй«ҳж•ҲгҖӮеӣ дёәеҰӮжһңйҖүжӢ©йҖҡиҝҮ INDEX_MERGE жқҘдјҳеҢ–жҹҘиҜўпјҢе°ұйЎ»иҰҒи®ҝй—®еӨҡдёӘзҙўеј•пјҢеҗҢж—¶иҝҳиҰҒе°ҶеҮ дёӘзҙўеј•иҝӣиЎҢ merge ж“ҚдҪңпјҢиҝҷеёҰжқҘзҡ„жҲҗжң¬еҸҜиғҪеҸҚиҖҢдјҡжҜ”йҖүжӢ©е…¶дёӯдёҖдёӘжңҖжңүж•Ҳзҡ„зҙўеј•жӣҙй«ҳгҖӮ
В
еңЁдёҖиҲ¬зҡ„еә”з”ЁеңәжҷҜдёӯпјҢеҸӘиҰҒдёҚжҳҜе…¶дёӯжҹҗдёӘиҝҮж»Өеӯ—ж®өеңЁеӨ§еӨҡж•°еңәжҷҜдёӢиғҪиҝҮж»Ө90%д»ҘдёҠзҡ„ж•°жҚ®пјҢиҖҢе…¶д»–зҡ„иҝҮж»Өеӯ—ж®өдјҡйў‘з№Ғзҡ„жӣҙж–°пјҢдёҖиҲ¬жӣҙеҖҫеҗ‘дәҺеҲӣе»әз»„еҗҲзҙўеј•пјҢ е°Өе…¶жҳҜеңЁе№¶еҸ‘йҮҸиҫғй«ҳзҡ„еңәжҷҜдёӢгҖӮеӣ дёәеҪ“并еҸ‘йҮҸиҫғй«ҳзҡ„ж—¶еҖҷпјҢеҚідҪҝеҸӘдёәжҜҸдёӘQueryиҠӮзңҒдәҶеҫҲе°‘зҡ„ IO ж¶ҲиҖ—пјҢдҪҶеӣ дёәжү§иЎҢйҮҸйқһеёёеӨ§пјҢжүҖиҠӮзңҒзҡ„иө„жәҗжҖ»йҮҸд»Қ然жҳҜйқһеёёеҸҜи§Ӯзҡ„гҖӮ
В
еҪ“然пјҢеҲӣе»әз»„еҗҲзҙўеј•е№¶дёҚжҳҜиҜҙе°ұйЎ»иҰҒе°ҶжҹҘиҜўжқЎд»¶дёӯзҡ„жүҖжңүеӯ—ж®өйғҪж”ҫеңЁдёҖдёӘзҙўеј•дёӯпјҢиҝҳеә”иҜҘе°ҪйҮҸи®©дёҖдёӘзҙўеј•иў«еӨҡдёӘ Query иҜӯеҸҘеҲ©з”ЁпјҢе°ҪйҮҸеҮҸе°‘еҗҢдёҖдёӘиЎЁдёҠзҡ„зҙўеј•ж•°йҮҸпјҢеҮҸе°‘еӣ дёәж•°жҚ®жӣҙж–°еёҰжқҘзҡ„зҙўеј•жӣҙж–°жҲҗжң¬пјҢеҗҢж—¶иҝҳеҸҜд»ҘеҮҸе°‘еӣ дёәзҙўеј•жүҖж¶ҲиҖ—зҡ„еӯҳеӮЁз©әй—ҙгҖӮ
жӯӨеӨ–пјҢMySQL иҝҳжҸҗдҫӣдәҶеҸҰеӨ–дёҖдёӘдјҳеҢ–зҙўеј•зҡ„еҠҹиғҪпјҢйӮЈе°ұжҳҜеүҚзјҖзҙўеј•гҖӮеңЁ MySQL дёӯпјҢеҸҜд»Ҙд»…д»…дҪҝз”ЁжҹҗдёӘеӯ—ж®өзҡ„еүҚйқўйғЁеҲҶеҶ…е®№еҒҡдёәзҙўеј•й”®зҙўеј•иҜҘеӯ—ж®өпјҢд»ҘиҫҫеҲ°еҮҸе°Ҹзҙўеј•еҚ з”Ёзҡ„еӯҳеӮЁз©әй—ҙе’ҢжҸҗй«ҳзҙўеј•и®ҝй—®ж•ҲзҺҮзҡ„зӣ®зҡ„гҖӮеҪ“然пјҢеүҚзјҖзҙўеј•зҡ„еҠҹиғҪд»…д»…йҖӮз”ЁдәҺ еӯ—ж®өеүҚзјҖйҡҸжңәйҮҚеӨҚжҖ§еҫҲе°Ҹзҡ„еӯ—ж®өгҖӮеҰӮжһңйЎ»иҰҒзҙўеј•зҡ„еӯ—ж®өеүҚзјҖеҶ…е®№жңүиҫғеӨҡзҡ„йҮҚеӨҚпјҢзҙўеј•зҡ„иҝҮж»ӨжҖ§иҮӘ然д№ҹдјҡйҡҸд№ӢйҷҚдҪҺпјҢйҖҡиҝҮзҙўеј•жүҖи®ҝй—®зҡ„ж•°жҚ®йҮҸе°ұдјҡеўһеҠ пјҢиҝҷж—¶еҖҷеүҚзјҖзҙў еј•иҷҪ然иғҪеӨҹеҮҸе°‘еӯҳеӮЁз©әй—ҙж¶ҲиҖ—пјҢдҪҶжҳҜеҸҜиғҪдјҡйҖ жҲҗ Query и®ҝй—®ж•ҲзҺҮзҡ„жһҒеӨ§йҷҚдҪҺпјҢеҫ—дёҚеҒҝеӨұгҖӮ
В
В
ж‘ҳиҮӘhttp://www.canphp.com/article/show-130.html
В
еӨҚеҗҲзҙўеј•дјҳеҢ–
дёӨдёӘжҲ–жӣҙеӨҡдёӘеҲ—дёҠзҡ„зҙўеј•иў«з§°дҪңеӨҚеҗҲзҙўеј•гҖӮ
еҲ©з”Ёзҙўеј•дёӯзҡ„йҷ„еҠ еҲ—пјҢжӮЁеҸҜд»Ҙзј©е°Ҹжҗңзҙўзҡ„иҢғеӣҙпјҢдҪҶдҪҝз”ЁдёҖдёӘе…·жңүдёӨеҲ—зҡ„зҙўеј•дёҚеҗҢдәҺдҪҝз”ЁдёӨдёӘеҚ•зӢ¬зҡ„зҙўеј•гҖӮеӨҚеҗҲзҙўеј•зҡ„з»“жһ„дёҺз”өиҜқз°ҝзұ»дјјпјҢдәәеҗҚз”ұ姓е’ҢеҗҚжһ„жҲҗпјҢз”өиҜқз°ҝ йҰ–е…ҲжҢү姓ж°ҸеҜ№иҝӣиЎҢжҺ’еәҸпјҢ然еҗҺжҢүеҗҚеӯ—еҜ№жңүзӣёеҗҢ姓ж°Ҹзҡ„дәәиҝӣиЎҢжҺ’еәҸгҖӮеҰӮжһңжӮЁзҹҘйҒ“姓пјҢз”өиҜқз°ҝе°Ҷйқһеёёжңүз”ЁпјӣеҰӮжһңжӮЁзҹҘйҒ“姓е’ҢеҗҚпјҢз”өиҜқз°ҝеҲҷжӣҙдёәжңүз”ЁпјҢдҪҶеҰӮжһңжӮЁеҸӘзҹҘйҒ“еҗҚдёҚ 姓пјҢз”өиҜқз°ҝе°ҶжІЎжңүз”ЁеӨ„гҖӮ
жүҖд»ҘиҜҙеҲӣе»әеӨҚеҗҲзҙўеј•ж—¶пјҢеә”иҜҘд»”з»ҶиҖғиҷ‘еҲ—зҡ„йЎәеәҸгҖӮеҜ№зҙўеј•дёӯзҡ„жүҖжңүеҲ—жү§иЎҢжҗңзҙўжҲ–д»…еҜ№еүҚеҮ еҲ—жү§иЎҢжҗңзҙўж—¶пјҢеӨҚеҗҲзҙўеј•йқһеёёжңүз”Ёпјӣд»…еҜ№еҗҺйқўзҡ„д»»ж„ҸеҲ—жү§иЎҢжҗңзҙўж—¶пјҢеӨҚеҗҲзҙўеј•еҲҷжІЎжңүз”ЁеӨ„гҖӮ
еҰӮпјҡе»әз«Ӣ 姓еҗҚгҖҒе№ҙйҫ„гҖҒжҖ§еҲ«зҡ„еӨҚеҗҲзҙўеј•гҖӮ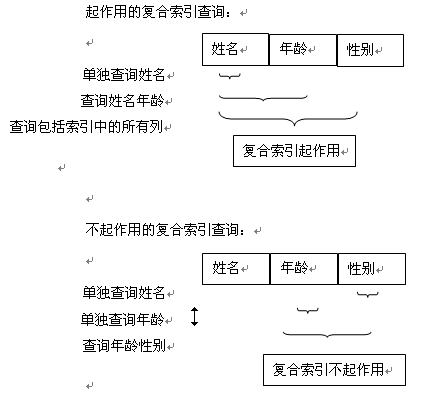
еӨҚеҗҲзҙўеј•зҡ„е»әз«ӢеҺҹеҲҷпјҡ
еҰӮжһңжӮЁеҫҲеҸҜиғҪд»…еҜ№дёҖдёӘеҲ—еӨҡж¬Ўжү§иЎҢжҗңзҙўпјҢеҲҷиҜҘеҲ—еә”иҜҘжҳҜеӨҚеҗҲзҙўеј•дёӯзҡ„第дёҖеҲ—гҖӮеҰӮжһңжӮЁеҫҲеҸҜиғҪеҜ№дёҖдёӘдёӨеҲ—зҙўеј•дёӯзҡ„дёӨдёӘеҲ—жү§иЎҢеҚ•зӢ¬зҡ„жҗңзҙўпјҢеҲҷеә”иҜҘеҲӣе»әеҸҰдёҖдёӘд»…еҢ…еҗ«з¬¬дәҢеҲ—зҡ„зҙўеј•гҖӮ
еҰӮдёҠеӣҫжүҖзӨәпјҢеҰӮжһңжҹҘиҜўдёӯйңҖиҰҒеҜ№е№ҙйҫ„е’ҢжҖ§еҲ«еҒҡжҹҘиҜўпјҢеҲҷеә”еҪ“еҶҚж–°е»әдёҖдёӘеҢ…еҗ«е№ҙйҫ„е’ҢжҖ§еҲ«зҡ„еӨҚеҗҲзҙўеј•гҖӮ
еҢ…еҗ«еӨҡдёӘеҲ—зҡ„дё»й”®е§Ӣз»ҲдјҡиҮӘеҠЁд»ҘеӨҚеҗҲзҙўеј•зҡ„еҪўејҸеҲӣе»әзҙўеј•пјҢе…¶еҲ—зҡ„йЎәеәҸжҳҜе®ғ们еңЁиЎЁе®ҡд№үдёӯеҮәзҺ°зҡ„йЎәеәҸпјҢиҖҢдёҚжҳҜеңЁдё»й”®е®ҡд№үдёӯжҢҮе®ҡзҡ„йЎәеәҸгҖӮеңЁиҖғиҷ‘е°ҶжқҘйҖҡиҝҮдё»й”®жү§иЎҢзҡ„жҗңзҙўпјҢзЎ®е®ҡе“ӘдёҖеҲ—еә”иҜҘжҺ’еңЁжңҖеүҚйқўгҖӮ
иҜ·жіЁж„ҸпјҢеҲӣе»әеӨҚеҗҲзҙўеј•еә”еҪ“еҢ…еҗ«е°‘ж•°еҮ дёӘеҲ—пјҢ并且иҝҷдәӣеҲ—з»ҸеёёеңЁselectжҹҘиҜўйҮҢдҪҝз”ЁгҖӮеңЁеӨҚеҗҲзҙўеј•йҮҢеҢ…еҗ«еӨӘеӨҡзҡ„еҲ—дёҚд»…дёҚдјҡз»ҷеёҰжқҘеӨӘеӨҡеҘҪеӨ„гҖӮиҖҢдё”з”ұдәҺдҪҝз”ЁзӣёеҪ“еӨҡзҡ„еҶ…еӯҳжқҘеӯҳеӮЁеӨҚеҗҲзҙўеј•зҡ„еҲ—зҡ„еҖјпјҢе…¶еҗҺжһңжҳҜеҶ…еӯҳжәўеҮәе’ҢжҖ§иғҪйҷҚдҪҺгҖӮ
В В В В В В В В
еӨҚеҗҲзҙўеј•еҜ№жҺ’еәҸзҡ„дјҳеҢ–пјҡ
еӨҚеҗҲзҙўеј•еҸӘеҜ№е’Ңзҙўеј•дёӯжҺ’еәҸзӣёеҗҢжҲ–зӣёеҸҚзҡ„order by иҜӯеҸҘдјҳеҢ–гҖӮ
еңЁеҲӣе»әеӨҚеҗҲзҙўеј•ж—¶пјҢжҜҸдёҖеҲ—йғҪе®ҡд№үдәҶеҚҮеәҸжҲ–иҖ…жҳҜйҷҚеәҸгҖӮеҰӮе®ҡд№үдёҖдёӘеӨҚеҗҲзҙўеј•пјҡ
- CREATEВ INDEXВ idx_exampleВ В В
- ONВ table1В (col1В ASC,В col2В DESC,В col3В ASC)В В
е…¶дёӯ жңүдёүеҲ—еҲҶеҲ«жҳҜпјҡcol1 еҚҮеәҸпјҢcol2 йҷҚеәҸпјҢ col3 еҚҮеәҸгҖӮзҺ°еңЁеҰӮжһңжҲ‘们жү§иЎҢдёӨдёӘжҹҘиҜў
1пјҡSelect col1, col2, col3 from table1 order by col1 ASC, col2 DESC, col3 ASC
В В е’Ңзҙўеј•йЎәеәҸзӣёеҗҢ
2пјҡSelect col1, col2, col3 from table1 order by col1 DESC, col2 ASC, col3 DESC
В е’Ңзҙўеј•йЎәеәҸзӣёеҸҚ
жҹҘиҜў1пјҢ2 йғҪеҸҜд»ҘеҲ«еӨҚеҗҲзҙўеј•дјҳеҢ–гҖӮ
еҰӮжһңжҹҘиҜўдёәпјҡ
Select col1, col2, col3 from table1 order by col1 ASC, col2 ASC, col3 ASC
В В жҺ’еәҸз»“жһңе’Ңзҙўеј•е®Ңе…ЁдёҚеҗҢж—¶пјҢжӯӨж—¶зҡ„жҹҘиҜўдёҚдјҡиў«еӨҚеҗҲзҙўеј•дјҳеҢ–гҖӮ
жҹҘиҜўдјҳеҢ–еҷЁеңЁеңЁwhereжҹҘиҜўдёӯзҡ„дҪңз”Ёпјҡ
еҰӮжһңдёҖдёӘеӨҡеҲ—зҙўеј•еӯҳеңЁдәҺ еҲ— Col1 е’Ң Col2 дёҠпјҢеҲҷд»ҘдёӢиҜӯеҸҘпјҡSelectВ В * from table whereВ В col1=val1 AND col2=val2 жҹҘиҜўдјҳеҢ–еҷЁдјҡиҜ•еӣҫйҖҡиҝҮеҶіе®ҡе“ӘдёӘзҙўеј•е°ҶжүҫеҲ°жӣҙе°‘зҡ„иЎҢгҖӮд№ӢеҗҺз”Ёеҫ—еҲ°зҡ„зҙўеј•еҺ»еҸ–еҖјгҖӮ
1пјҺ еҰӮжһңеӯҳеңЁдёҖдёӘеӨҡеҲ—зҙўеј•пјҢд»»дҪ•жңҖе·Ұйқўзҡ„зҙўеј•еүҚзјҖиғҪиў«дјҳеҢ–еҷЁдҪҝз”ЁгҖӮжүҖд»ҘиҒ”еҗҲзҙўеј•зҡ„йЎәеәҸдёҚеҗҢпјҢеҪұе“Қзҙўеј•зҡ„йҖүжӢ©пјҢе°ҪйҮҸе°ҶеҖје°‘зҡ„ж”ҫеңЁеүҚйқўгҖӮ
еҰӮпјҡдёҖдёӘеӨҡеҲ—зҙўеј•дёә (col1 пјҢcol2пјҢ col3)
В В В йӮЈд№ҲеңЁзҙўеј•еңЁеҲ— (col1) гҖҒ(col1 col2) гҖҒ(col1 col2 col3) зҡ„жҗңзҙўдјҡжңүдҪңз”ЁгҖӮ
В
- SELECTВ *В FROMВ tbВ WHEREВ В col1В =В val1 В В
- SELECTВ *В FROMВ tbВ WHEREВ В col1В =В val1В andВ col2В =В val2 В В
- SELECTВ *В FROMВ tbВ WHEREВ В col1В =В val1В andВ col2В =В val2В В ANDВ col3В =В val3В В
2пјҺ еҰӮжһңеҲ—дёҚжһ„жҲҗзҙўеј•зҡ„жңҖе·ҰйқўеүҚзјҖпјҢеҲҷе»әз«Ӣзҡ„зҙўеј•е°ҶдёҚиө·дҪңз”ЁгҖӮ
еҰӮпјҡ
- SELECTВ *В FROMВ В tbВ WHEREВ В col3В =В val3 В В
- SELECTВ *В FROMВ В tbВ В WHEREВ В col2В =В val2 В В
- SELECTВ *В FROMВ В tbВ В WHEREВ В col2В =В val2В В andВ В col3=val3В В
3пјҺ еҰӮжһңдёҖдёӘ Like иҜӯеҸҘзҡ„жҹҘиҜўжқЎд»¶дёҚд»ҘйҖҡй…Қз¬Ұиө·е§ӢеҲҷдҪҝз”Ёзҙўеј•гҖӮ
еҰӮпјҡ%иҪҰ жҲ– %иҪҰ%В В дёҚдҪҝз”Ёзҙўеј•гҖӮ
В В В иҪҰ%В В В В В В В В В В В В В дҪҝз”Ёзҙўеј•гҖӮ
зҙўеј•зҡ„зјәзӮ№пјҡ
1.В В В В В В еҚ з”ЁзЈҒзӣҳз©әй—ҙгҖӮ
2.В В В В В В еўһеҠ дәҶжҸ’е…Ҙе’ҢеҲ йҷӨзҡ„ж“ҚдҪңж—¶й—ҙгҖӮдёҖдёӘиЎЁжӢҘжңүзҡ„зҙўеј•и¶ҠеӨҡпјҢжҸ’е…Ҙе’ҢеҲ йҷӨзҡ„йҖҹеәҰи¶Ҡж…ўгҖӮеҰӮ иҰҒжұӮеҝ«йҖҹеҪ•е…Ҙзҡ„зі»з»ҹдёҚе®ңе»әиҝҮеӨҡзҙўеј•гҖӮ
дёӢйқўжҳҜдёҖдәӣеёёи§Ғзҡ„зҙўеј•йҷҗеҲ¶й—®йўҳ
1гҖҒдҪҝз”ЁдёҚзӯүдәҺж“ҚдҪңз¬Ұ(<>, !=)
дёӢйқўиҝҷз§Қжғ…еҶөпјҢеҚідҪҝеңЁеҲ—dept_idжңүдёҖдёӘзҙўеј•пјҢжҹҘиҜўиҜӯеҸҘд»Қ然жү§иЎҢдёҖж¬Ўе…ЁиЎЁжү«жҸҸ
select * from dept where staff_num <> 1000;
дҪҶжҳҜејҖеҸ‘дёӯзҡ„зЎ®йңҖиҰҒиҝҷж ·зҡ„жҹҘиҜўпјҢйҡҫйҒ“жІЎжңүи§ЈеҶій—®йўҳзҡ„еҠһжі•дәҶеҗ—пјҹ
жңүпјҒ
йҖҡиҝҮжҠҠз”Ё or иҜӯжі•жӣҝд»ЈдёҚзӯүеҸ·иҝӣиЎҢжҹҘиҜўпјҢе°ұеҸҜд»ҘдҪҝз”Ёзҙўеј•пјҢд»ҘйҒҝе…Қе…ЁиЎЁжү«жҸҸпјҡдёҠйқўзҡ„иҜӯеҸҘж”№жҲҗдёӢйқўиҝҷж ·зҡ„пјҢе°ұеҸҜд»ҘдҪҝз”Ёзҙўеј•дәҶгҖӮ
- selectВ *В fromВ deptВ shereВ staff_numВ <В 1000В orВ dept_idВ >В 1000;В В
2гҖҒдҪҝз”Ё is null жҲ– is not null
дҪҝз”Ё is null жҲ–is nuo nullд№ҹдјҡйҷҗеҲ¶зҙўеј•зҡ„дҪҝз”ЁпјҢеӣ дёәж•°жҚ®еә“并没жңүе®ҡд№үnullеҖјгҖӮеҰӮжһңиў«зҙўеј•зҡ„еҲ—дёӯжңүеҫҲеӨҡnullпјҢе°ұдёҚдјҡдҪҝз”ЁиҝҷдёӘзҙўеј•пјҲйҷӨйқһзҙўеј•жҳҜдёҖдёӘдҪҚеӣҫзҙўеј•пјҢе…ідәҺдҪҚеӣҫ зҙўеј•пјҢдјҡеңЁд»ҘеҗҺзҡ„blogж–Үз« йҮҢеҒҡиҜҰз»Ҷи§ЈйҮҠпјүгҖӮеңЁsqlиҜӯеҸҘдёӯдҪҝз”ЁnullдјҡйҖ жҲҗеҫҲеӨҡйә»зғҰгҖӮ
и§ЈеҶіиҝҷдёӘй—®йўҳзҡ„еҠһжі•е°ұжҳҜпјҡе»әиЎЁж—¶жҠҠйңҖиҰҒзҙўеј•зҡ„еҲ—е®ҡд№үдёәйқһз©ә(not null)
3гҖҒдҪҝз”ЁеҮҪж•°
еҰӮжһңжІЎжңүдҪҝз”ЁеҹәдәҺеҮҪж•°зҡ„зҙўеј•пјҢйӮЈд№ҲwhereеӯҗеҸҘдёӯеҜ№еӯҳеңЁзҙўеј•зҡ„еҲ—дҪҝз”ЁеҮҪж•°ж—¶пјҢдјҡдҪҝдјҳеҢ–еҷЁеҝҪз•ҘжҺүиҝҷдәӣзҙўеј•гҖӮдёӢйқўзҡ„жҹҘиҜўе°ұдёҚдјҡдҪҝз”Ёзҙўеј•пјҡ
- selectВ *В fromВ staffВ whereВ trunc(birthdate)В =В '01-MAY-82';В В
дҪҶжҳҜжҠҠеҮҪж•°еә”з”ЁеңЁжқЎд»¶дёҠпјҢзҙўеј•жҳҜеҸҜд»Ҙз”ҹж•Ҳзҡ„пјҢжҠҠдёҠйқўзҡ„иҜӯеҸҘж”№жҲҗдёӢйқўзҡ„иҜӯеҸҘпјҢе°ұеҸҜд»ҘйҖҡиҝҮзҙўеј•иҝӣиЎҢжҹҘжүҫгҖӮ
- selectВ *В fromВ staffВ whereВ birthdateВ <В (to_date('01-MAY-82')В +В 0.9999);В В
4гҖҒжҜ”иҫғдёҚеҢ№й…Қзҡ„ж•°жҚ®зұ»еһӢ
жҜ”иҫғдёҚеҢ№й…Қзҡ„ж•°жҚ®зұ»еһӢд№ҹжҳҜйҡҫдәҺеҸ‘зҺ°зҡ„жҖ§иғҪй—®йўҳд№ӢдёҖгҖӮ
дёӢйқўзҡ„дҫӢеӯҗдёӯпјҢdept_idжҳҜдёҖдёӘvarchar2еһӢзҡ„еӯ—ж®өпјҢеңЁиҝҷдёӘеӯ—ж®өдёҠжңүзҙўеј•пјҢдҪҶжҳҜдёӢйқўзҡ„иҜӯеҸҘдјҡжү§иЎҢе…ЁиЎЁжү«жҸҸгҖӮ
- selectВ *В fromВ deptВ whereВ dept_idВ =В 900198;В В
иҝҷжҳҜеӣ дёәoracleдјҡиҮӘеҠЁжҠҠwhereеӯҗеҸҘиҪ¬жҚўжҲҗto_number(dept_id)=900198пјҢе°ұжҳҜ3жүҖиҜҙзҡ„жғ…еҶөпјҢиҝҷж ·е°ұйҷҗеҲ¶дәҶзҙўеј•зҡ„дҪҝз”ЁгҖӮ
жҠҠSQLиҜӯеҸҘж”№дёәеҰӮдёӢеҪўејҸе°ұеҸҜд»ҘдҪҝз”Ёзҙўеј•
- selectВ *В fromВ deptВ whereВ dept_idВ =В '900198';В В
жҒ©пјҢиҝҷйҮҢиҝҳжңүиҰҒжіЁж„Ҹзҡ„пјҡ
жқҘиҮӘиҖҒзҺӢзҡ„еҚҡе®ўпјҲhttp://hi.baidu.com/thinkinginlamp/blog/item/9940728be3986015c8fc7a85.htmlпјү
жҜ”ж–№иҜҙжңүдёҖдёӘж–Үз« иЎЁпјҢжҲ‘们иҰҒе®һзҺ°жҹҗдёӘзұ»еҲ«дёӢжҢүж—¶й—ҙеҖ’еәҸеҲ—иЎЁжҳҫзӨәеҠҹиғҪпјҡ
SELECT * FROM articles WHERE category_id = ... ORDER BY created DESC LIMIT ...
иҝҷж ·зҡ„жҹҘиҜўеҫҲеёёи§ҒпјҢеҹәжң¬дёҠдёҚз®Ўд»Җд№Ҳеә”з”ЁйҮҢйғҪиғҪжүҫеҮәдёҖеӨ§жҠҠзұ»дјјзҡ„SQLжқҘпјҢеӯҰйҷўжҙҫзҡ„иҜ»иҖ…зңӢеҲ°дёҠйқўзҡ„SQLпјҢеҸҜиғҪдјҡиҜҙSELECT *дёҚеҘҪпјҢеә”иҜҘд»…д»…жҹҘиҜўйңҖиҰҒзҡ„еӯ—ж®өпјҢйӮЈжҲ‘们е°ұзҙўжҖ§еҪ»еә•зӮ№пјҢжҠҠSQLж”№жҲҗеҰӮдёӢзҡ„еҪўејҸпјҡ
SELECT id FROM articles WHERE category_id = ... ORDER BY created DESC LIMIT ...
В
жҲ‘们еҒҮи®ҫиҝҷйҮҢзҡ„idжҳҜдё»й”®пјҢиҮідәҺж–Үз« зҡ„е…·дҪ“еҶ…е®№пјҢеҸҜд»ҘйғҪдҝқеӯҳеҲ°memcachedд№Ӣзұ»зҡ„й”®еҖјзұ»еһӢзҡ„зј“еӯҳйҮҢпјҢеҰӮжӯӨдёҖжқҘпјҢеӯҰйҷўжҙҫзҡ„иҜ»иҖ…们еә”иҜҘжҢ‘дёҚеҮәд»Җд№ҲжҜӣз—…жқҘдәҶпјҢдёӢйқўжҲ‘们е°ұжҢүиҝҷжқЎSQLжқҘиҖғиҷ‘еҰӮдҪ•е»әз«Ӣзҙўеј•пјҡ
дёҚиҖғиҷ‘ж•°жҚ®еҲҶеёғд№Ӣзұ»зҡ„зү№ж®Ҡжғ…еҶөпјҢд»»дҪ•дёҖдёӘеҗҲж јзҡ„WEBејҖеҸ‘дәәе‘ҳйғҪзҹҘйҒ“зұ»дјјиҝҷж ·зҡ„SQLпјҢеә”иҜҘе»әз«ӢдёҖдёӘвҖқcategory_id, createdвҖңеӨҚеҗҲзҙўеј•пјҢдҪҶиҝҷжҳҜжңҖдҪізӯ”жЎҲдёҚпјҹдёҚи§Ғеҫ—пјҢзҺ°еңЁжҳҜеӣһеӨҙзңӢзңӢж Үйўҳзҡ„ж—¶еҖҷдәҶпјҡMySQLйҮҢе»әз«Ӣзҙўеј•еә”иҜҘиҖғиҷ‘ж•°жҚ®еә“еј•ж“Һзҡ„зұ»еһӢпјҒ
еҰӮжһңжҲ‘们зҡ„ж•°жҚ®еә“еј•ж“ҺжҳҜInnoDBпјҢйӮЈд№Ҳе»әз«ӢвҖқcategory_id, createdвҖңеӨҚеҗҲзҙўеј•жҳҜжңҖдҪізӯ”жЎҲгҖӮи®©жҲ‘们зңӢзңӢInnoDBзҡ„зҙўеј•з»“жһ„пјҢеңЁInnoDBйҮҢпјҢзҙўеј•з»“жһ„жңүдёҖдёӘзү№ж®Ҡзҡ„ең°ж–№пјҡйқһдё»й”®зҙўеј•еңЁе…¶BTreeзҡ„еҸ¶иҠӮ зӮ№дёҠдјҡйўқеӨ–дҝқеӯҳеҜ№еә”дё»й”®зҡ„еҖјпјҢиҝҷж ·еҒҡдёҖдёӘжңҖзӣҙжҺҘзҡ„еҘҪеӨ„е°ұжҳҜCovering IndexпјҢдёҚз”ЁеҶҚеҲ°ж•°жҚ®ж–Ү件йҮҢеҺ»еҸ–idзҡ„еҖјпјҢеҸҜд»ҘзӣҙжҺҘеңЁзҙўеј•йҮҢеҫ—еҲ°е®ғгҖӮ
еҰӮжһңжҲ‘们зҡ„ж•°жҚ®еә“еј•ж“ҺжҳҜMyISAMпјҢйӮЈд№Ҳе»әз«Ӣ"category_id, created"еӨҚеҗҲзҙўеј•е°ұдёҚжҳҜжңҖдҪізӯ”жЎҲгҖӮеӣ дёәMyISAMзҡ„зҙўеј•з»“жһ„йҮҢпјҢйқһдё»й”®зҙўеј•е№¶жІЎжңүйўқеӨ–дҝқеӯҳеҜ№еә”дё»й”®зҡ„еҖјпјҢжӯӨж—¶еҰӮжһңжғіеҲ©з”ЁдёҠCovering IndexпјҢеә”иҜҘе»әз«Ӣ"category_id, created, id"еӨҚеҗҲзҙўеј•гҖӮ
е” е®ҢдәҶпјҢеә”иҜҘжҳҺзҷҪжҲ‘зҡ„ж„ҸжҖқдәҶеҗ§гҖӮеёҢжңӣд»ҘеҗҺеӨ§е®¶еңЁиҖғиҷ‘зҙўеј•зҡ„ж—¶еҖҷиғҪжҖқиҖғзҡ„жӣҙе…ЁйқўдёҖзӮ№пјҢе®һйҷ…еә”з”ЁдёӯиҝҳжңүеҫҲеӨҡзұ»дјјзҡ„й—®йўҳпјҢжҜ”еҰӮиҜҙеӨҡж•°дәәеңЁе»әз«Ӣзҙўеј•зҡ„ж—¶еҖҷдёҚд»Һ CardinalityпјҲSHOW INDEX FROM ...иғҪзңӢеҲ°жӯӨеҸӮж•°пјүзҡ„и§’еәҰзңӢжҳҜеҗҰеҗҲйҖӮзҡ„й—®йўҳпјҢCardinalityиЎЁзӨәе”ҜдёҖеҖјзҡ„дёӘж•°пјҢдёҖиҲ¬жқҘиҜҙпјҢеҰӮжһңе”ҜдёҖеҖјдёӘж•°еңЁжҖ»иЎҢж•°дёӯжүҖеҚ жҜ”дҫӢе°ҸдәҺ20%зҡ„иҜқпјҢеҲҷ еҸҜд»Ҙи®ӨдёәCardinalityеӨӘе°ҸпјҢжӯӨж—¶зҙўеј•йҷӨдәҶжӢ–ж…ўinsert/update/deleteзҡ„йҖҹеәҰд№ӢеӨ–пјҢдёҚдјҡеҜ№selectдә§з”ҹеӨӘеӨ§дҪңз”ЁпјӣиҝҳжңүдёҖдёӘ з»ҶиҠӮжҳҜе»әз«Ӣзҙўеј•зҡ„ж—¶еҖҷжңӘиҖғиҷ‘еӯ—з¬ҰйӣҶзҡ„еҪұе“ҚпјҢжҜ”еҰӮиҜҙusernameеӯ—ж®өпјҢеҰӮжһңд»…д»…е…Ғи®ёиӢұж–ҮпјҢдёӢеҲ’зәҝд№Ӣзұ»зҡ„з¬ҰеҸ·пјҢйӮЈд№Ҳе°ұдёҚиҰҒз”ЁgbkпјҢutf-8д№Ӣзұ»зҡ„еӯ—з¬Ұ йӣҶпјҢиҖҢеә”иҜҘдҪҝз”Ёlatin1жҲ–иҖ…asciiиҝҷз§Қз®ҖеҚ•зҡ„еӯ—з¬ҰйӣҶпјҢзҙўеј•ж–Ү件дјҡе°ҸеҫҲеӨҡпјҢйҖҹеәҰиҮӘ然е°ұдјҡеҝ«еҫҲеӨҡгҖӮиҝҷдәӣз»ҶиҠӮй—®йўҳйңҖиҰҒиҜ»иҖ…иҮӘе·ұеӨҡжіЁж„ҸпјҢжҲ‘е°ұдёҚеӨҡиҜҙдәҶгҖӮ



зӣёе…іжҺЁиҚҗ
MongDBзҡ„зҙўеј•еҲҶдёәд»ҘдёӢеҮ з§Қзұ»еһӢпјҡеҚ•й”®зҙўеј•гҖҒеӨҚеҗҲзҙўеј•гҖҒеӨҡй”®зҙўеј•гҖҒең°зҗҶз©әй—ҙзҙўеј•гҖҒе…Ёж–Үжң¬зҙўеј•е’Ңе“ҲеёҢзҙўеј•еңЁдёҖдёӘй”®дёҠеҲӣе»әзҡ„зҙўеј•е°ұжҳҜеҚ•й”®зҙўеј•пјҢеҚ•й”®зҙўеј•жҳҜжңҖеёёи§Ғзҡ„зҙўеј•пјҢеҰӮMongoDBй»ҳи®ӨеҲӣе»әзҡ„_idзҡ„зҙўеј•е°ұжҳҜеҚ•й”®зҙўеј•гҖӮ...
MongoDBж”ҜжҢҒзҡ„зҙўеј•з§Қзұ»еҫҲеӨҡпјҢиҜёеҰӮеҚ•й”®зҙўеј•пјҢеӨҚеҗҲзҙўеј•пјҢеӨҡй”®зҙўеј•пјҢTTLзҙўеј•пјҢж–Үжң¬зҙўеј•пјҢз©әй—ҙең°зҗҶзҙўеј•зӯүгҖӮеҗҢж—¶зҙўеј•зҡ„еұһжҖ§еҸҜд»Ҙе…·жңүе”ҜдёҖжҖ§пјҢеҚіе”ҜдёҖзҙўеј•гҖӮе”ҜдёҖзҙўеј•з”ЁдәҺзЎ®дҝқзҙўеј•еӯ—ж®өдёҚеӯҳеӮЁйҮҚеӨҚзҡ„еҖјпјҢеҚіејәеҲ¶зҙўеј•еӯ—ж®өзҡ„е”ҜдёҖжҖ§...
еҗҢж—¶пјҢж·ұе…ҘжҺўи®ЁMongoDBзҙўеј•зҡ„зұ»еһӢпјҲеҰӮеҚ•й”®зҙўеј•гҖҒеӨҚеҗҲзҙўеј•гҖҒеӨҡй”®зҙўеј•зӯүпјүпјҢ并еҲҶжһҗзҙўеј•зҡ„еҲӣе»әгҖҒз®ЎзҗҶе’ҢдјҳеҢ–зӯ–з•ҘгҖӮжӯӨеӨ–пјҢж–Үз« иҝҳд»Ӣз»ҚдәҶзҙўеј•еҜ№жҹҘиҜўжҖ§иғҪзҡ„еҪұе“ҚпјҢеҢ…жӢ¬еҰӮдҪ•йҖҡиҝҮexplain()ж–№жі•еҲҶжһҗжҹҘиҜўе’Ңзҙўеј•ж•ҲзҺҮпјҢд»ҘеҸҠиҰҶзӣ–жҹҘиҜў...
дё»й”®иҮӘеҠЁе»әз«Ӣе”ҜдёҖзҙўеј• йў‘з№ҒдҪңдёәжҹҘиҜўжқЎд»¶зҡ„еӯ—ж®өеә”иҜҘе»әз«Ӣ...еҚ•й”®/з»„еҗҲзҙўеј•зҡ„йҖүжӢ©й—®йўҳпјҢwhoпјҹпјҲеңЁй«ҳ并еҸ‘дёӢеҖҫеҗ‘еҲӣе»әз»„еҗҲзҙўеј•пјү жҹҘиҜўдёӯжҺ’еәҸзҡ„еӯ—ж®өпјҢжҺ’еәҸеӯ—ж®өиӢҘйҖҡиҝҮзҙўеј•еҺ»и®ҝй—®е°ҶеӨ§еӨ§жҸҗй«ҳжҺ’еәҸйҖҹеәҰ жҹҘиҜўдёӯз»ҹи®ЎжҲ–жҳҜеҲҶз»„зҡ„еӯ—ж®ө
еҚ•й”®иҜҶеҲ«зЁӢеәҸ
Multisim 12.0д»ҝзңҹ5vеҚ•й”®ејҖе…із”өи·ҜпјҢиҝҳдёҚеӨӘжҲҗзҶҹпјҢй«ҳжүӢдҝ®ж”№
51еҚ•зүҮжңәдёҠз”ЁжұҮзј–иҜӯиЁҖе®һзҺ°зҡ„еҚ•й”®иҜҶеҲ«еәҸзЁӢеәҸ
гҖҗе®һйӘҢ21гҖ‘зӢ¬з«ӢжҢүй”®еҚ•й”®жҺ§еҲ¶з»§з”өеҷЁ.zipжәҗз ҒarduinoдҫӢзЁӢжәҗз ҒGL9дҫӢзЁӢжәҗд»Јз ҒгҖҗе®һйӘҢ21гҖ‘зӢ¬з«ӢжҢүй”®еҚ•й”®жҺ§еҲ¶з»§з”өеҷЁ.zipжәҗз ҒarduinoдҫӢзЁӢжәҗз ҒGL9дҫӢзЁӢжәҗд»Јз ҒгҖҗе®һйӘҢ21гҖ‘зӢ¬з«ӢжҢүй”®еҚ•й”®жҺ§еҲ¶з»§з”өеҷЁ.zipжәҗз ҒarduinoдҫӢзЁӢжәҗз ҒGL9дҫӢзЁӢжәҗ...
еҜ№еҚ•й”®зұ»SingleTonзҡ„д»Јз Ғе®һзҺ°...еңЁж¬ЎеҹәзЎҖдёҠиҜҫд»ҘиҜҘзј–дёәеҸӘиғҪе®һдҫӢеҢ–nж¬Ўзҡ„зұ»..
йҷ„件дёӯеҢ…еҗ« еҮ з§Қ еёёи§Ғ зҡ„ еҚ•й”® ејҖе…іжңәз”өи·Ҝ жң¬дәәдәІиҮӘиҜ•йӘҢ иҝҮ з…§з”өи·ҜиҝһжҺҘеҸҜд»Ҙе®һзҺ° еҚ•й”®ејҖе…іжңә
еҚ•й”®иҜҶеҲ«е®һйӘҢгҖҗCиҜӯиЁҖгҖ‘.zip
SingletonжЁЎејҸпјҢйЎҫеҗҚжҖқд№үпјҢSingletonе°ұжҳҜзЎ®дҝқдёҖдёӘзұ»еҸӘжңүе”ҜдёҖзҡ„дёҖдёӘе®һдҫӢгҖӮSingletonдё»иҰҒз”ЁдәҺеҜ№иұЎзҡ„еҲӣе»әпјҢиҝҷж„Ҹе‘ізқҖпјҢеҰӮжһңжҹҗдёӘзұ»йҮҮз”ЁдәҶSingletonжЁЎејҸпјҢеҲҷеңЁиҝҷдёӘзұ»иў«еҲӣе»әеҗҺпјҢе®ғе°Ҷжңүдё”д»…жңүдёҖдёӘе®һдҫӢеҸҜдҫӣи®ҝй—®гҖӮ...
еҚ•й”®еӨҡеҠҹиғҪиҜҶеҲ«жҠҖжңҜгҖҗжұҮзј–иҜӯиЁҖгҖ‘.zip
еҚ•й”®ејҖе…іжңәпјҢй«ҳжүӢеҒҡзҡ„зәҜ硬件з”өи·ҜпјҢеҸҜд»ҘеҸӮиҖғдёҖдёӢ
еҚ•й”®и§Ұж‘ёиҠҜзүҮеҲқж¬ЎдёҠз”өеүҚ NCи„ҡдҪҚеҝ…йңҖжӮ¬з©әпјҢDIYO8001 е…ұжңү 4 з§ҚеҠҹиғҪеҸҜйҖүпјҢз”ұ OP1/OP2 з®Ўи„ҡ дёҠз”өеүҚзҡ„иҝһжҺҘзҠ¶жҖҒеҶіе®ҡгҖӮе…·дҪ“еҰӮдёӢпјҡ (1)еҠҹиғҪ 1пјҡOP1&OP2; е…ЁйғЁжҺҘең°пјҢеҸҜеҒҡ LED дёүж®өи§ҰжҺ§и°ғе…ү(дҪҺ->дёӯ->й«ҳ->зҒӯ)еҫӘзҺҜ; (2)еҠҹиғҪ 2пјҡ...
51ејҖеҸ‘жқҝе®һдҫӢж•ҷзЁӢ__еҚ•й”®иҜҶеҲ« ејҖеҸ‘иҜӯиЁҖпјҡCиҜӯиЁҖ
дёәAndroidжүӢжңәзҡ„йҖүеҚ•й”®еҸҠиҝ”еӣһй”®еҠ е…ҘеҠҹиғҪ Posted on 2013е№ҙ04жңҲ19ж—Ҙ by U3d / Unity3D еҹәзЎҖж•ҷзЁӢ/иў«еӣҙи§Ӯ 246 ж¬Ў еӨ§йғЁд»Ҫ
еҚ•зүҮжңәCиҜӯиЁҖеҚ•й”®еӨҚз”ЁжҠҖжңҜпјҢдёҖдёӘжҢүй”®е®һзҺ°дёүз§ҚеӨҚз”ЁпјҡеҚ•еҮ»гҖҒеҸҢеҮ»гҖҒй•ҝеҮ»гҖӮе·ІйӘҢиҜҒеҸҜйқ ең°иҝҗиЎҢгҖӮдҫӢзЁӢйҮҮз”ЁSTM8Lеә“еҮҪж•°зј–еҶҷпјҢзЁҚдҪңдҝ®ж”№дҫҝеҸҜд»Ҙ移жӨҚгҖӮ
еҚ•й”®ејҖе…із”өи·Ҝ(еёҰз”өжұ е……з”өз”өи·Ҝ),жңүжҲ‘иҮӘе·ұеҸӮиҖғи®ҫи®Ўзҡ„,еёҢжңӣиғҪз»ҷеҒҡ硬件з”өи·Ҝзҡ„еҗҢеҝ—дёҖзӮ№дҪңз”Ё.